1. Scikit-learn là gì?
Nếu bạn đang sử dụng Python và đang muốn tìm một thư viện mạnh mẽ mà bạn có thể mang các thuật toán học máy (machine learning) vào trong một hệ thống thì không còn thư viện nào thích hợp hơn scikit-learn. Thư viện này tích hợp rất nhiều thuật toán hiện đại và cố điển giúp bạn vừa học vừa tiến hành đưa ra các giải pháp hữu ích cho bài toán của bạn một cách đơn giản.
Scikit-learn (Sklearn) là thư viện mạnh mẽ nhất dành cho các thuật toán học máy được viết trên ngôn ngữ Python. Thư viện cung cấp một tập các công cụ xử lý các bài toán machine learning và statistical modeling gồm: classification, regression, clustering, và dimensionality reduction.
Thư viện được cấp phép bản quyền chuẩn FreeBSD và chạy được trên nhiều nền tảng Linux. Scikit-learn được sử dụng như một tài liệu để học tập.
Để cài đặt scikit-learn trước tiên phải cài thư viện SciPy (Scientific Python). Những thành phần gồm:
- Numpy: Gói thư viện xử lý dãy số và ma trận nhiều chiều
- SciPy: Gói các hàm tính toán logic khoa học
- Matplotlib: Biểu diễn dữ liệu dưới dạng đồ thị 2 chiều, 3 chiều
- IPython: Notebook dùng để tương tác trực quan với Python
- SymPy: Gói thư viện các kí tự toán học
- Pandas: Xử lý, phân tích dữ liệu dưới dạng bảng
Những thư viện mở rộng của SciPy thường được đặt tên dạng SciKits. Như thư viện này là gói các lớp, hàm sử dụng trong thuật toán học máy thì được đặt tên là scikit-learn.
Scikit-learn hỗ trợ mạnh mẽ trong việc xây dựng các sản phẩm. Nghĩa là thư viện này tập trung sâu trong việc xây dựng các yếu tố: dễ sử dụng, dễ code, dễ tham khảo, dễ làm việc, hiệu quả cao.
Mặc dù được viết cho Python nhưng thực ra các thư viện nền tảng của scikit-learn lại được viết dưới các thư viện của C để tăng hiệu suất làm việc. Ví dụ như: Numpy(Tính toán ma trận), LAPACK, LibSVM và Cython.
2. Thuật toán :
Thư viện tập trung vào việc mô hình hóa dữ liệu. Nó không tập trung vào việc truyền tải dữ liệu, biến đổi hay tổng hợp dữ liệu. Những công việc này dành cho thư viện Numpy và Pandas.
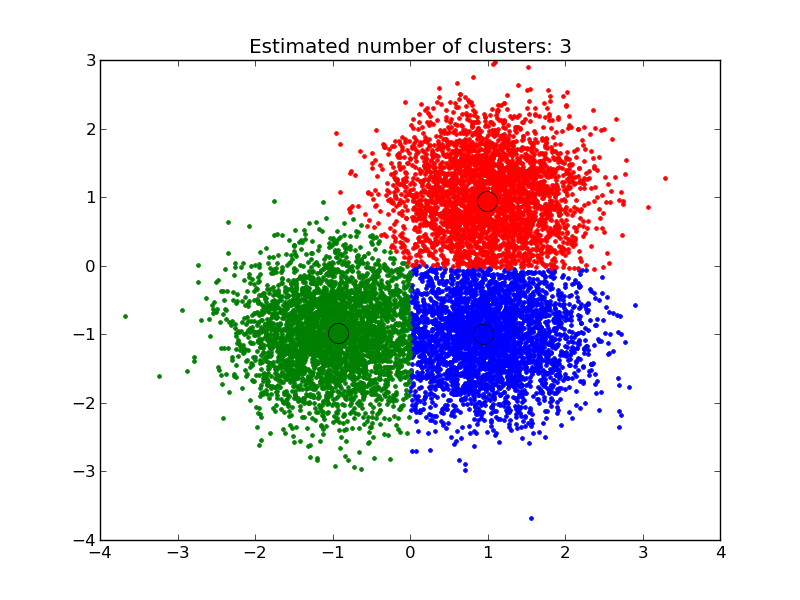
Sau đâu là một số nhóm thuật toán được xây dựng bởi thư viện scikit-learn:
- Clustering: Nhóm thuật toán Phân cụm dữ liệu không gán nhãn. Ví dụ thuật toán KMeans
- Cross Validation: Kiểm thử chéo, đánh giá độ hiệu quả của thuật toán học giám sát sử dụng dữ liệu kiểm thử (validation data) trong quá trình huấn luyện mô hình.
- Datasets: Gồm nhóm các Bộ dữ liệu được tích hợp sẵn trong thư viện. Hầu như các bộ dữ liệu đều đã được chuẩn hóa và mang lại hiêu suất cao trong quá trình huấn luyện như iris, digit, …
- Dimensionality Reduction: Mục đích của thuật toán này là để Giảm số lượng thuộc tính quan trọng của dữ liệu bằng các phương pháp như tổng hợp, biểu diễn dữ liệu và lựa chọn đặc trưng. Ví dụ thuật toán PCA (Principal component analysis).
- Ensemble methods: Các Phương pháp tập hợp sử dụng nhiều thuật toán học tập để có được hiệu suất dự đoán tốt hơn so với bất kỳ thuật toán học cấu thành nào.
- Feature extraction: Trích xuất đặc trưng. Mục đích là để định nghĩa các thuộc tình với dữ liệu hình ảnh và dữ liệu ngôn ngữ.
- Feature selection: Trích chọn đặc trưng. Lựa chọn các đặc trưng có ý nghĩa trong việc huấn luyện mô hình học giám sát.
- Parameter Tuning: Tinh chỉnh tham số. Các thuật toán phục vụ việc lựa chọn tham số phù hợp để tối ưu hóa mô hình.
- Manifold Learning: Các thuật toán học tổng hợp và Phân tích dữ liệu đa chiều phức tạp.
- Supervised Models: Học giám sát. Mảng lớn các thuật toán học máy hiện nay. Ví dụ như linear models, discriminate analysis, naive bayes, lazy methods, neural networks, support vector machines và decision trees.
Chúng ta đi tìm hiểu một ví dụ cụ thể sau
3. Ví du
(Classification and Regression Trees)
Tôi muốn cho bạn một ví dụ để cho bạn thấy việc sử dụng thư viện dễ dàng như thế nào.
Ở ví dụ sau, chúng ta sử dụng cây quyết định Decision tree phân loại để mô hình hóa bộ dữ liệu hoa Iris.
Bộ dữ liệu này được cung cấp dưới dạng tập dữ liệu mẫu với thư viện và được tải. Trình phân loại phù hợp với dữ liệu và sau đó dự đoán được thực hiện trên dữ liệu đào tạo.
Bộ dữ liệu này được cung cấp dưới dạng tập dữ liệu mẫu ngay trong thư viện sau đó được tải xuống. Thuật toán phân loại bắt đầu huấn luyện mô hình với bộ dữ liệu Iris ban đầu sau đó dự đoán lại các dữ liệu huấn luyện.
Cuối cùng, chúng ta đánh giá độ tốt của mô hình bằng quan sát accuracy và confusion matrix của 2 tập nhãn thực tế và nhãn dự đoán của mô hình.
# Sample Decision Tree Classifier
from sklearn import datasets
from sklearn import metrics
from sklearn.tree import DecisionTreeClassifier
# load the iris datasets
dataset = datasets.load_iris()
# fit a CART model to the data
model = DecisionTreeClassifier()
model.fit(dataset.data, dataset.target)
print(model)
# make predictions
expected = dataset.target
predicted = model.predict(dataset.data)
# summarize the fit of the model
print(metrics.classification_report(expected, predicted))
print(metrics.confusion_matrix(expected, predicted))Chạy ví dụ trên được kết quả như sau. Bạn có thể thấy chi tiết mô hình cây phân loại được huấn luyện với các tham số chi tiết như thế nào, mỗi tham số ảnh hưởng rất lớn tới việc mô hình có tốt hay không. Phía dưới là classification report và confusion matrix của mô hình.
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
precision recall f1-score support
0 1.00 1.00 1.00 50
1 1.00 1.00 1.00 50
2 1.00 1.00 1.00 50
avg / total 1.00 1.00 1.00 150
[[50 0 0]
[ 0 50 0]
[ 0 0 50]]