Pandas DataFrame là một cấu trúc chứa dữ liệu hai chiều và các nhãn tương ứng của nó. DataFrames được sử dụng rộng rãi trong data science, machine learning, scientific computing và nhiều lĩnh vực sử dụng nhiều dữ liệu khác.
DataFrames tương tự như SQL tables hoặc bảng tính mà bạn làm việc trong Excel hoặc Calc. Trong nhiều trường hợp, DataFrame nhanh hơn, dễ sử dụng hơn và mạnh hơn bảng hoặc spreadsheets vì chúng là một phần không thể thiếu của hệ sinh thái Python và NumPy. Trong bài hướng dẫn này, chúng ta sẽ học:
- Pandas DataFrame là gì và cách khởi tạo
- Làm thế nào access, modify, add, sort, filter, và delete data
- Cách xử lý missing values
- Cách làm việc với time-series data
- Cách nhanh chóng visualize dữ liệu
Bắt đầu nào… Let’s go!!!
Nội dung
1. Giới thiệu Pandas DataFrame
Pandas DataFrames là cấu trúc dữ liệu chứa:
- Dữ liệu được tổ chức theo không gian 2 chiều bao rows và columns
- Các Labels tương ứng với rows và columns
Bạn có thể bắt đầu làm việc với DataFrames bằng cách import Pandas:
Python:
>>> import pandas as pdHãy tưởng tượng bạn đang sử dụng Pandas để phân tích dữ liệu về các ứng viên cho vị trí phát triển ứng dụng web bằng Python. Giả sử bạn quan tâm đến tên, thành phố, độ tuổi và điểm số của ứng viên trong bài kiểm tra lập trình Python hoặc điểm số py-score:
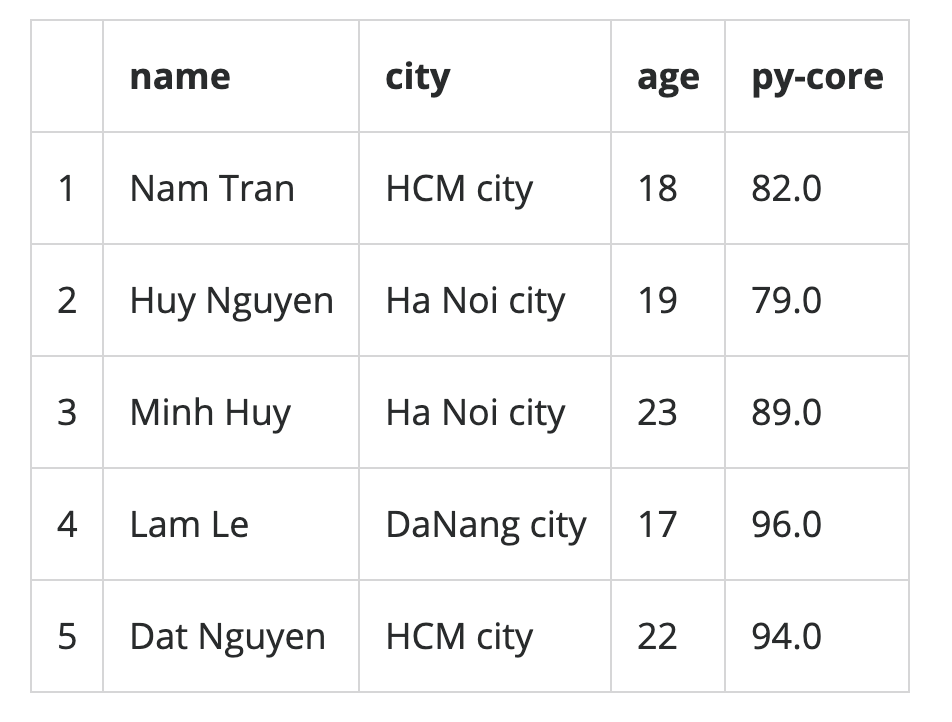
Trong bảng này, hàng đầu tiên chứa các nhãn cột (tên, thành phố, tuổi và điểm số). Cột đầu tiên chứa các nhãn hàng (1, 2, v.v.). Tất cả các ô khác được điền với các giá trị dữ liệu.
Bây giờ bạn có mọi thứ bạn cần để tạo Pandas DataFrame.
Có một số cách để tạo Pandas DataFrame. Trong hầu hết các trường hợp, bạn sẽ sử dụng hàm tạo DataFrame và cung cấp dữ liệu, nhãn và thông tin khác. Bạn có thể chuyển dữ liệu dưới dạng danh sách hai chiều, bộ tuple hoặc mảng NumPy. Bạn cũng có thể chuyển nó dưới dạng từ điển hoặc phiên bản Pandas Series hoặc dưới dạng một trong số các kiểu dữ liệu khác không được đề cập trong hướng dẫn này.
Đối với ví dụ này, giả sử bạn đang sử dụng từ điển để chuyển dữ liệu:
>>> data = {
'name': ['Nam Tran', 'Huy Nguyen', 'Minh Huy', 'Lam Le', 'Dat Nguyen'],
'city': ['HCM city', 'Ha Noi city', 'Ha Noi city', 'Da Nang city', 'HCM city'],
'age': [18, 19, 23, 17, 22],
'py-core': [82.0, 79.0, 89.0, 96.0, 94.0]
}
>>> row_labels = [1, 2, 3, 4, 5]data là một biến Python tham chiếu đến từ điển chứa dữ liệu ứng viên của bạn. Nó cũng chứa các nhãn của các cột:
- ‘name’
- ‘city’
- ‘age’
- ‘py-core’
Cuối cùng, row_labels đề cập đến một danh sách chứa các nhãn của các hàng, là các số từ 1 đến 5.
Bây giờ bạn đã sẵn sàng tạo Pandas DataFrame:
>>> df = pd.DataFrame(data=data, index=row_labels)
>>> df
name city age py-score
1 Nam Tran HCM city 18 82.0
2 Huy Nguyen Ha Noi city 19 79.0
3 Minh Huy Ha Noi city 23 89.0
4 Lam Le Da Nang city 17 96.0
5 Dat Nguyen HCM city 22 94.0df là một biến chứa tham chiếu đến Pandas DataFrame của bạn. Pandas DataFrame này trông giống như bảng ứng cử viên ở trên và có các tính năng sau:
- Row labels từ 1 đến 5
- Column labels là ‘name’, ‘city’, ‘age’, and ‘py-score’
- Data là các dữ liệu: names, cities, ages, và điểm py-core
Pandas DataFrames đôi khi dữ liệu có thể rất lớn, khiến việc xem xét tất cả các hàng cùng một lúc là không thực tế. Bạn có thể sử dụng .head() để hiển thị một số mục đầu tiên và .tail() để hiển thị một số mục cuối cùng:
>>> df.head(n=2)
name city age py-score
1 Nam Tran HCM city 18 82.0
2 Huy Nguyen Ha Noi city 19 79.0
>>> df.tail(n=2)
4 Lam Le Da Nang city 17 96.0
5 Dat Nguyen HCM city 22 94.0Đó là cách bạn có thể hiển thị phần đầu hoặc phần cuối của Pandas DataFrame. Tham số n chỉ định số hàng sẽ hiển thị.
Lưu ý: Có thể hữu ích khi coi Pandas DataFrame như một từ điển gồm các cột, hoặc Chuỗi Pandas, với nhiều tính năng bổ sung.
Bạn có thể truy cập một cột trong Pandas DataFrame giống như cách bạn lấy giá trị từ từ điển:
>>> cities = df['city']
>>> cities
1 HCM city
2 Ha Noi city
3 Ha Noi city
4 Da Nang city
5 HCM city
Name: city, dtype: objectĐó là cách bạn có được một cột cụ thể. Bạn đã trích xuất cột tương ứng với nhãn ‘city’, chứa vị trí của tất cả các dữ liệu của bạn muốn làm việc cùng.
Mỗi cột của Pandas DataFrame là một ví dụ của pandas.Series, một cấu trúc chứa dữ liệu một chiều và labels của chúng. Bạn có thể lấy một mục của đối tượng Dòng (row) giống như cách bạn làm với từ điển, bằng cách sử dụng labels của nó làm khóa.
>>> cities[3]
'Ha Noi city'Trong trường hợp này, ‘Ha Noi city’ là giá trị dữ liệu và ‘3’ là label tương ứng. Như bạn sẽ thấy trong phần sau, có nhiều cách khác để lấy một mục cụ thể trong Pandas DataFrame.
Bạn cũng có thể truy cập toàn bộ hàng bằng trình truy cập .loc []:
>>> df.loc[3]
name Minh Huy
city 'Ha Noi city'
age 23
py-core 89.0
Name: 3, dtype: objectLần này, bạn đã trích xuất hàng tương ứng với label 3, chứa dữ liệu cho ứng cử viên có tên là Minh Huy. Ngoài các giá trị dữ liệu từ hàng này, bạn đã trích xuất nhãn của các cột tương ứng.
Dữ liệu trả về cũng là một ví dụ của pandas.Series.
2. Khởi tạo một Pandas DataFrame
Như đã đề cập, có một số cách để tạo Pandas DataFrame. Trong phần này, chúng ta sẽ học cách thực hiện việc này bằng cách sử dụng hàm tạo DataFrame cùng với:
- Python dictionaries
- Python lists
- Mãng 2 chiều NumPy
- Files
Bạn có thể bắt đầu bằng cách import Pandas cùng với NumPy, mà bạn sẽ sử dụng trong ví dụ sau:
>>> import numpy as np
>>> import pandas as pdTạo Pandas DataFrame với Dictionaries
Như bạn đã thấy, bạn có thể tạo Pandas DataFrame bằng Python dictionary:
>>> d = {'x': [1, 2, 3], 'y': np.array([2, 4, 8]), 'z': 100}
>>> pd.DataFrame(d)
x y z
0 1 2 100
1 2 4 100
2 3 8 100Khóa của dictionary là label cột của DataFrame và giá trị từ điển là giá trị dữ liệu trong các cột DataFrame tương ứng. Các giá trị có thể được chứa trong một tuple, list, mảng NumPy một chiều, Pandas Series object, hoặc một trong số các kiểu dữ liệu khác. Bạn cũng có thể cung cấp một giá trị duy nhất sẽ được sao chép dọc theo toàn bộ cột.
Có thể kiểm soát thứ tự của các cột bằng thông số cột và nhãn hàng bằng chỉ mục:
>>> pd.DataFrame(d, index=[100, 200, 300], columns=['z', 'y', 'x'])
z y x
100 100 2 1
200 100 4 2
300 100 8 3Như bạn có thể thấy, bạn đã chỉ định các nhãn hàng 100, 200 và 300. Bạn cũng đã buộc thứ tự của các cột: z, y, x.
3. Tạo Pandas DataFrame với Lists
Một cách khác để tạo Pandas DataFrame là sử dụng list của dictionary:
>>> l = [{'x': 1, 'y': 2, 'z': 100},
... {'x': 2, 'y': 4, 'z': 100},
... {'x': 3, 'y': 8, 'z': 100}]
>>> pd.DataFrame(l)
x y z
0 1 2 100
1 2 4 100
2 3 8 100Một lần nữa, các key của dictionary là label cột và giá trị dictionary là giá trị dữ liệu trong DataFrame.
Bạn cũng có thể sử dụng nested list hoặc list of lists làm giá trị dữ liệu. Nếu bạn làm vậy, thì bạn nên chỉ định rõ ràng nhãn của cột, hàng hoặc cả hai khi bạn tạo DataFrame:
>>> l = [[1, 2, 100],
... [2, 4, 100],
... [3, 8, 100]]
>>> pd.DataFrame(l, columns=['x', 'y', 'z'])
x y z
0 1 2 100
1 2 4 100
2 3 8 100Đó là cách bạn có thể sử dụng nested list để tạo Pandas DataFrame. Bạn cũng có thể sử dụng list of tuples theo cách tương tự. Để làm như vậy, chỉ cần thay thế các nested liststrong ví dụ trên bằng tuples.
4. Tạo Pandas DataFrame với NumPy Arrays
Bạn có thể truyền array NumPy hai chiều vào phương thức khởi tạo DataFrame giống như cách bạn làm với danh sách:
>>> arr = np.array([[1, 2, 100],
... [2, 4, 100],
... [3, 8, 100]])
>>> df_ = pd.DataFrame(arr, columns=['x', 'y', 'z'])
>>> df_
x y z
0 1 2 100
1 2 4 100
2 3 8 100Mặc dù ví dụ này trông gần giống với cách triển khai nested list ở trên, nhưng nó có một ưu điểm: Bạn có thể chỉ định copy tham số tùy chọn.
Khi copy được đặt thành False (default setting), dữ liệu từ array NumPy sẽ không được sao chép. Điều này có nghĩa là dữ liệu gốc từ array được gán cho Pandas DataFrame. Nếu bạn sửa đổi array, thì DataFrame của bạn cũng sẽ thay đổi:
>>> arr[0, 0] = 1000
>>> df_
x y z
0 1000 2 100
1 2 4 100
2 3 8 100Như bạn thấy, khi bạn thay đổi mục đầu tiên của arr, bạn cũng sửa đổi df_.
Lưu ý: Việc không copy các giá trị dữ liệu có thể giúp bạn tiết kiệm đáng kể thời gian và sức mạnh xử lý khi làm việc với các tập dữ liệu lớn
Nếu hành động này không như bạn muốn, thì bạn nên chỉ định copy = True trong hàm tạo DataFrame. Bằng cách đó, df_ sẽ được tạo với một bản sao của các giá trị từ arr thay vì các giá trị thực.
5. Tạo Pandas DataFrame với từ Files
Bạn có thể lưu và tải dữ liệu và label từ Pandas DataFrame đến và từ một số loại tệp, bao gồm CSV, Excel, SQL, JSON, v.v. Đây là một tính năng rất mạnh mẽ.
Bạn có thể lưu dữ liệu từ DataFrame của mình vào tệp CSV với .to_csv ():
>>> df.to_csv('data.csv')Câu lệnh trên sẽ tạo ra một tệp CSV có tên data.csv trong thư mục làm việc của bạn:
>>> pd.read_csv('data.csv', index_col=0)
name city age py-score
1 Nam Tran HCM city 18 82.0
2 Huy Nguyen Ha Noi city 19 79.0
3 Minh Huy Ha Noi city 23 89.0
4 Lam Le Da Nang city 17 96.0
5 Dat Nguyen HCM city 22 94.0Đó là cách bạn đọc và lấy dữ liệu Pandas DataFrame từ một tệp. Trong trường hợp này, index_col = 0 chỉ định rằng các nhãn hàng nằm trong cột đầu tiên của tệp CSV.