Để tạo bộ phân loại, chúng ta phải chuẩn bị dữ liệu ở định dạng được yêu cầu bởi mô-đun xây dựng bộ phân loại. Chúng tôi chuẩn bị dữ liệu bằng cách thực hiện One Hot Encoding
1. Encoding Data
Ta sẽ thảo luận về ý nghĩa của việc mã hóa dữ liệu. Đầu tiên, chạy đoạn code sau:
In [10]: # creating one hot encoding of the categorical columns.
data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])Như trong command, câu lệnh trên sẽ tạo ra one hot encoding.Nó đã tạo ra những gì? Kiểm tra dữ liệu đã tạo được gọi là “data” như sau :
In [11]: data.head()Kết quả như sau :
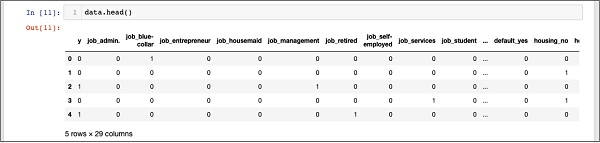
Để hiểu dữ liệu trên, ta sẽ liệt kê tên cột bằng cách chạy lệnh data.columns
In [12]: data.columns
Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'job_unknown', 'marital_divorced', 'marital_married', 'marital_single',
'marital_unknown', 'default_no', 'default_unknown', 'default_yes',
'housing_no', 'housing_unknown', 'housing_yes', 'loan_no',
'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent',
'poutcome_success'], dtype='object')Bây giờ, mình sẽ giải thích cách one hot encoding thực hiện bằng lệnh get_dummies. Cột đầu tiên trong cơ sở dữ liệu mới được tạo là trường “y” cho biết liệu khách hàng này đã đăng ký TD hay chưa. Bây giờ, hãy xem xét các cột được mã hóa. Cột được mã hóa đầu tiên là “job”. Trong cơ sở dữ liệu, bạn sẽ thấy rằng cột “job” có nhiều giá trị có thể có như “admin”, “blue-collar”, “entrepreneur”, v.v. Đối với mỗi giá trị có thể, một cột mới được tạo trong cơ sở dữ liệu, với tên cột được thêm vào dưới dạng tiền tố.
Do đó, ta có các cột được gọi là “job_admin”, “job_blue-Neck”, v.v. Đối với mỗi trường được mã hóa trong cơ sở dữ liệu gốc , bạn sẽ tìm thấy danh sách các cột được thêm vào cơ sở dữ liệu đã tạo với tất cả các giá trị có thể mà cột đó nhận trong cơ sở dữ liệu gốc. Kiểm tra cẩn thận danh sách các cột để hiểu cách dữ liệu được ánh xạ tới cơ sở dữ liệu mới.
2. Hiểu về Data Mapping (Ánh xạ dữ liệu) :
Để hiểu dữ liệu được tạo, ta sẽ in ra toàn bộ dữ liệu bằng lệnh data. Kết quả như sau
In [13]: data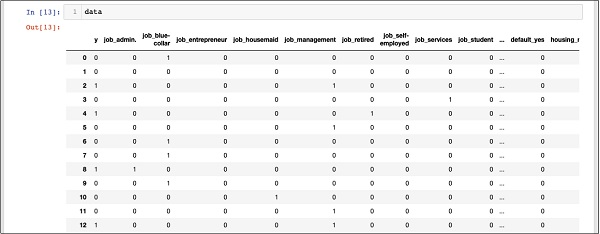
Màn hình trên hiển thị mười hai hàng đầu tiên. Nếu bạn cuộn xuống thêm, bạn sẽ thấy rằng ánh xạ được thực hiện cho tất cả các hàng.
Một phần màn hình xuất ra bên dưới cơ sở dữ liệu được hiển thị ở đây để bạn tham khảo.
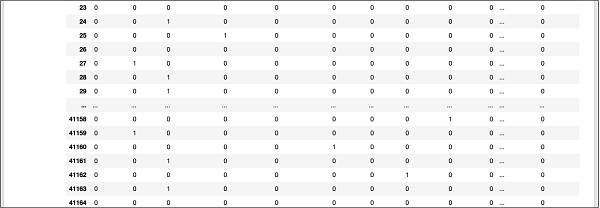
Để hiểu dữ liệu được ánh xạ(mapped), chúng ta hãy kiểm tra hàng đầu tiên.
Nó nói rằng khách hàng này chưa đăng ký TD như được chỉ ra bởi giá trị trong trường “y”. Khách hàng này là khách hàng“blue-collar”. Cuộn xuống theo chiều ngang, nó sẽ cho bạn biết rằng anh ta có“housing”và không có“loan” nào.
Tai cần xử lý thêm một số dữ liệu trước khi có thể bắt đầu xây dựng mô hình của mình.
3. Dropping giá trị “unknown”
Nếu ta kiểm tra các cột trong cơ sở dữ liệu được ánh xạ, bạn sẽ thấy sự hiện diện của một số cột kết thúc bằng “không xác định”(unknown). Ví dụ: kiểm tra cột ở chỉ mục 12 bằng lệnh sau được hiển thị trong ảnh chụp màn hình:
In [14]: data.columns[12]
Out[14]: 'job_unknown'Điều này cho thấy công việc khách hàng được chỉ định là không xác định. Rõ ràng, không có ích gì khi đưa các cột như vậy vào phân tích và xây dựng mô hình cả. Do đó, tất cả các cột có giá trị “không xác định” sẽ bị loại bỏ. Điều này được thực hiện như sau:
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)Đảm bảo rằng bạn chỉ định số cột chính xác. Trong trường hợp không chắc chắn, bạn có thể kiểm tra tên cột bất cứ lúc nào bằng cách chỉ định chỉ mục của nó trong lệnh cột như được mô tả trước đó.
Sau khi loại bỏ các cột không mong muốn, bạn có thể kiểm tra danh sách cuối cùng của các cột như sau:
In [16]: data.columns
Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'marital_divorced', 'marital_married', 'marital_single', 'default_no',
'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes',
'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'],
dtype='object')Bây giờ dữ liệu đã sẵn sàng xây dựng mô hình