4. Tạo tín hiệu âm thanh đơn điệu :
Hai bước mà bạn đã thấy rất quan trọng để tìm hiểu về các tín hiệu. Bây giờ, bước này sẽ hữu ích nếu bạn muốn tạo tín hiệu âm thanh với một số thông số được xác định trước. Lưu ý rằng bước này sẽ lưu tín hiệu âm thanh trong tệp đầu ra.
Trong ví dụ sau, ta sẽ tạo một tín hiệu đơn điệu, sử dụng Python, sẽ được lưu trữ trong một tệp
import numpy as np
import matplotlib.pyplot as plt
from scipy.io.wavfile import writeCung cấp tệp nơi tệp đầu ra sẽ được lưu
output_file = 'audio_signal_generated.wav' chỉ định các tham số bạn chọn như sau :
duration = 4 # in seconds
frequency_sampling = 44100 # in Hz
frequency_tone = 784
min_val = -4 * np.pi
max_val = 4 * np.piTrong bước này, chúng ta có thể tạo ra tín hiệu âm thanh
t = np.linspace(min_val, max_val, duration * frequency_sampling)
audio_signal = np.sin(2 * np.pi * tone_freq * t)Lưu tệp âm thanh trong tệp đầu ra :
write(output_file, frequency_sampling, signal_scaled)Trích xuất 100 giá trị đầu tiên cho biểu đồ
audio_signal = audio_signal[:100]
time_axis = 1000 * np.arange(0, len(signal), 1) / float(sampling_freq)Hình dung tín hiệu âm thanh được tạo ra như sau:
plt.plot(time_axis, signal, color='blue')
plt.xlabel('Time in milliseconds')
plt.ylabel('Amplitude')
plt.title('Generated audio signal')
plt.show()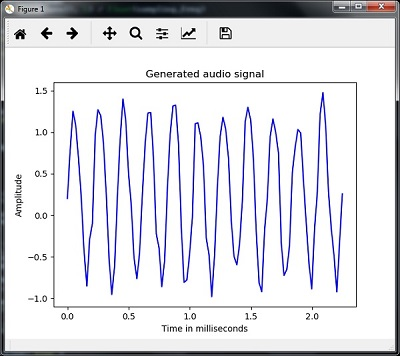
5. Tính năng trích xuất từ giọng nói :
Đây là bước quan trọng nhất trong việc xây dựng bộ nhận dạng giọng nói vì sau khi chuyển đổi tín hiệu giọng nói sang miền tần số, chúng ta phải chuyển nó thành dạng đặc trưng có thể sử dụng được. Chúng tôi có thể sử dụng các kỹ thuật trích xuất tính năng khác nhau như MFCC, PLP, PLP-RASTA, v.v. cho mục đích này.
Trong ví dụ sau, mình sẽ trích xuất các tính năng từ tín hiệu, từng bước, sử dụng Python, bằng cách sử dụng kỹ thuật MFCC.
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from python_speech_features import mfcc, logfbankBây giờ, hãy đọc tệp âm thanh được lưu trữ. Nó sẽ trả về hai giá trị – tần số lấy mẫu và tín hiệu âm thanh. Cung cấp đường dẫn của tệp âm thanh nơi nó được lưu trữ.
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav")Lưu ý rằng ở đây mình đang lấy 15000 mẫu đầu tiên để phân tích.
audio_signal = audio_signal[:15000]Sử dụng các kỹ thuật của MFCC và thực hiện lệnh sau để trích xuất các tính năng của MFCC
features_mfcc = mfcc(audio_signal, frequency_sampling)In các tham số MFCC như sau :
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0])
print('Length of each feature =', features_mfcc.shape[1])Vẽ features MFCC như sau :
features_mfcc = features_mfcc.T
plt.matshow(features_mfcc)
plt.title('MFCC')Ta sẽ làm việc với filter bank features , đầu tiên cần phải extract filtter bank features :
filterbank_features = logfbank(audio_signal, frequency_sampling)In các đối số filter bank
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0])
print('Length of each feature =', filterbank_features.shape[1])Vẽ và visualize filter bank features :
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()Theo kết quả của các bước trên, bạn có thể quan sát các kết quả đầu ra sau: Hình 1 cho MFCC và Hình 2 cho Filter Bank :
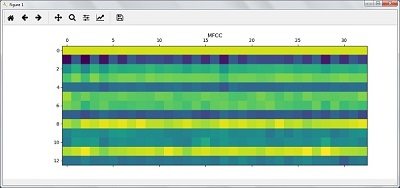
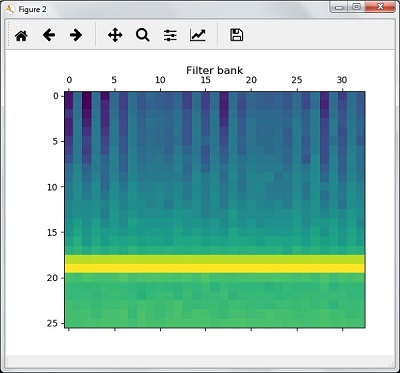
6. Nhận biết các từ đã nói :
Nhận dạng giọng nói có nghĩa là khi con người đang nói, một cỗ máy sẽ hiểu nó. Ở đây, mình đang sử dụng Google Speech API bằng Python để biến điều đó thành hiện thực
- Pyaudio : pip íntall Pyaudio
- SpeechRecognition : pip install SpeechRecognition.
- Google-Speech-API : pip install google-api-python-client
Quan sát ví dụ sau để hiểu về nhận dạng lời nói :
import speech_recognition as srTạo object như sau :
recording = sr.Recognizer()Bây giờ, mô-đun Micrô () sẽ lấy giọng nói làm đầu vào :
with sr.Microphone() as source: recording.adjust_for_ambient_noise(source)
print("Please Say something:")
audio = recording.listen(source)Bây giờ Google API sẽ nhận dạng giọng nói và đưa ra đầu ra.
try:
print("You said: \n" + recording.recognize_google(audio))
except Exception as e:
print(e)Output như sau ;
Please Say Something:
You said: