6. Tạo ANN Perceptron nhiều lớp :
Ta đã tìm hiểu cách tạo, biên dịch và đào tạo các mô hình Keras.Bây giờ ta sẽ tạo ANN dựa trên MPL đơn giản.
a. Dataset module
Trước khi tạo mô hình, ta cần chọn một vấn đề, cần thu thập dữ liệu cần thiết và chuyển dữ liệu sang mảng NumPy. Sau khi dữ liệu được thu thập, chúng tôi có thể chuẩn bị và đào tạo mô hình bằng cách sử dụng dữ liệu đã thu thập. Thu thập dữ liệu là một trong những giai đoạn khó khăn nhất của học máy. Keras cung cấp một mô-đun đặc biệt, bộ dữ liệu để tải xuống dữ liệu máy học trực tuyến để huấn luyện. Nó lấy dữ liệu từ máy chủ trực tuyến, xử lý dữ liệu và trả về dữ liệu dưới dạng tập huấn luyện và kiểm tra. Dữ liệu có sẵn trong mô-đun như sau,
- CIFAR10 Phân loại hình ảnh nhỏ
- CIFAR100 Phân loại hình ảnh nhỏ
- IMDB Movie đánh giá phân loại tình cảm
- Reuters newswire phân loại chủ đề
- Cơ sở dữ liệu MNIST của các chữ số viết tay
- Cơ sở dữ liệu của Fashion-MNIST về các bài báo thời trang
- Tập dữ liệu hồi quy giá nhà ở Boston
Ta sẽ sử dụng cơ sở dữ liệu MNIST gồm các chữ số viết tay (hoặc minst) làm đầu vào . Minst là một bộ sưu tập các hình ảnh màu xám 60.000, 28×28. Nó chứa 10 chữ số. Nó cũng chứa 10.000 hình ảnh thử nghiệm.
Đoạn code sau đây có thể được sử dụng để tải tập dữ liệu –
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()Trong đó :
- Dòng 1 nhập minst từ mô-đun tập dữ liệu keras.
- Dòng 3 gọi hàm load_data, hàm này sẽ tìm nạp dữ liệu từ máy chủ trực tuyến và trả về dữ liệu dưới dạng 2 bộ, Bộ đầu tiên, (x_train, y_train) đại diện cho dữ liệu đào tạo có hình dạng, (number_sample, 28, 28) và nhãn chữ số của nó với shape, (number_samples,). Bộ thứ hai, (x_test, y_test) đại diện cho dữ liệu thử nghiệm có cùng hình dạng.
Tập dữ liệu khác cũng có thể được tìm nạp bằng cách sử dụng API tương tự và mọi API cũng trả về dữ liệu tương tự ngoại trừ hình dạng của dữ liệu. Hình dạng của dữ liệu phụ thuộc vào loại dữ liệu.
b. Tạo model :
Chọn perceptron nhiều lớp đơn giản (MLP) như được trình bày bên dưới và tạo mô hình bằng Keras.
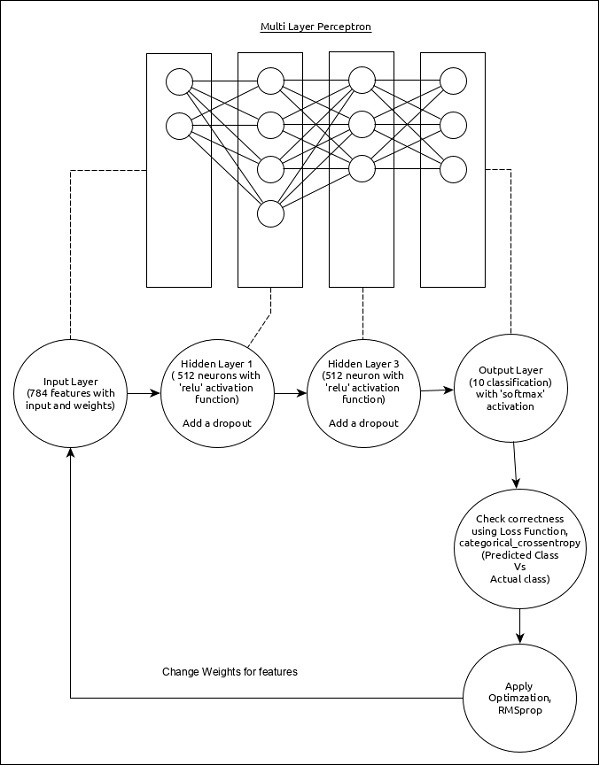
Các tính năng cốt lõi của mô hình như sau:
- Lớp đầu vào bao gồm 784 giá trị (28 x 28 = 784).
- Lớp hidden đầu tiên, Dense bao gồm 512 tế bào thần kinh và chức năng kích hoạt ‘relu’.
- Lớp hidden thứ hai, Dropout có giá trị là 0,2.
- Lớp hidden thứ ba, một lần nữa là Dense bao gồm 512 nơ ron và hàm activation ‘relu’.
- Lớp hidden thứ tư, Dropout có giá trị là 0,2.
- Lớp thứ năm và cuối cùng bao gồm 10 nơ ron và hàm activation ‘softmax’.
- Sử dụng categorical_crossentropy làm hàm mất mát.
- Sử dụng RMSprop () làm Trình tối ưu hóa.
- Sử dụng độ chính xác làm thước đo.
- batch size là 128
- epochs là 20
Bước 1 − Import các thư viện cần thiết
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import numpy as npBước 2 − Load dữ liệu
(x_train, y_train), (x_test, y_test) = mnist.load_data()Bước 3 − Xử lý dữ liệu
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)Trong đó :
- reshape được sử dụng để định hình lại đầu vào từ (28, 28) tuple thành (784,)
- to_categorical được sử dụng để chuyển đổi vectơ sang ma trận nhị phân
Bước 4 − Tạo model
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax'))Bước 5 − Biên dịch mô hình
model.compile(loss = 'categorical_crossentropy',
optimizer = RMSprop(),
metrics = ['accuracy'])Bước 6 − Huấn luyện mô hìnhSử dụng phương thức fit()
history = model.fit(
x_train, y_train,
batch_size = 128,
epochs = 20,
verbose = 1,
validation_data = (x_test, y_test)
)7. Tổng kết :
Mình đã tạo một mô hình, tải dữ liệu và đào tạo dữ liệu cho mô hình. Bây giờ cần đánh giá mô hình và dự đoán đầu ra cho đầu vào chưa biết, ta sẽ nghiên cứu trong bài sau
Việc thực thi ứng dụng sẽ đưa ra nội dung bên dưới dưới dạng đầu ra:
Train on 60000 samples, validate on 10000 samples Epoch 1/20
60000/60000 [==============================] - 7s 118us/step - loss: 0.2453
- acc: 0.9236 - val_loss: 0.1004 - val_acc: 0.9675 Epoch 2/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.1023
- acc: 0.9693 - val_loss: 0.0797 - val_acc: 0.9761 Epoch 3/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.0744
- acc: 0.9770 - val_loss: 0.0727 - val_acc: 0.9791 Epoch 4/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.0599
- acc: 0.9823 - val_loss: 0.0704 - val_acc: 0.9801 Epoch 5/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0504
- acc: 0.9853 - val_loss: 0.0714 - val_acc: 0.9817 Epoch 6/20
60000/60000 [==============================] - 7s 111us/step - loss: 0.0438
- acc: 0.9868 - val_loss: 0.0845 - val_acc: 0.9809 Epoch 7/20
60000/60000 [==============================] - 7s 114us/step - loss: 0.0391
- acc: 0.9887 - val_loss: 0.0823 - val_acc: 0.9802 Epoch 8/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0364
- acc: 0.9892 - val_loss: 0.0818 - val_acc: 0.9830 Epoch 9/20
60000/60000 [==============================] - 7s 113us/step - loss: 0.0308
- acc: 0.9905 - val_loss: 0.0833 - val_acc: 0.9829 Epoch 10/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0289
- acc: 0.9917 - val_loss: 0.0947 - val_acc: 0.9815 Epoch 11/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0279
- acc: 0.9921 - val_loss: 0.0818 - val_acc: 0.9831 Epoch 12/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0260
- acc: 0.9927 - val_loss: 0.0945 - val_acc: 0.9819 Epoch 13/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0257
- acc: 0.9931 - val_loss: 0.0952 - val_acc: 0.9836 Epoch 14/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0229
- acc: 0.9937 - val_loss: 0.0924 - val_acc: 0.9832 Epoch 15/20
60000/60000 [==============================] - 7s 115us/step - loss: 0.0235
- acc: 0.9937 - val_loss: 0.1004 - val_acc: 0.9823 Epoch 16/20
60000/60000 [==============================] - 7s 113us/step - loss: 0.0214
- acc: 0.9941 - val_loss: 0.0991 - val_acc: 0.9847 Epoch 17/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0219
- acc: 0.9943 - val_loss: 0.1044 - val_acc: 0.9837 Epoch 18/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0190
- acc: 0.9952 - val_loss: 0.1129 - val_acc: 0.9836 Epoch 19/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0197
- acc: 0.9953 - val_loss: 0.0981 - val_acc: 0.9841 Epoch 20/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0198
- acc: 0.9950 - val_loss: 0.1215 - val_acc: 0.9828